上篇screen(股票筛选器)之二 -- 回测,没有全面调查就没有伤害 解决了回测过程中碰到的种种陷阱,并对原来在构建portfolio时使用等权重的方式进行优化,给出了一个基于股票流通市值为基础可灵活设置的权重分配方式。经过修改后的策略已经可以获得不错的收益。
本篇主要目标是对另一个参数—aggregate z-score的权重进行优化。回顾本系列的第一篇一个基于价值的screen(筛选器) -- 大概是最简单的量化投资,在里面我们使用下面8个因子(factor):
- Price
- EV / EBIT
- Risk
- book debt-to-equity ratio
- Change in book D/E
- ACCRUAL = (NI-CFO)/TA
- Growth
- Revenue growth
- M3M = 3-Month price change
- Quality
- ROIC
- Change in ROIC
并分别计算这8个因子的z-score,在计算aggregate z-score的时候,使用等权重的方式,即简单地将这8个z-score加总。在文中也提到,这种方式的好处就是简单,也不用担心overfitting。但一个很明显的问题是它忽略了数据内部隐藏的信息,即每个因子的z-score在预测股票收益时重要性是不一样的,并且还忽略了不同因子之间存在的相关性(correlation)。那么,肯定还是有一种更好的方法来组合这些z-score,使得最后生成的portfolio能更优。
Panel Regression
一种比较常见的优化方法是通过线性回归对权重进行优化,具体来说就是投资组合的管理者收集对应股票收益的时间序列,例如月度收益,再结合相关因子在每月初的z-score,然后在数据样本的时间区间(period)内运行截面回归(cross-sectional regression),也就是面板数据回归(panel regression),从而获得最优的z-score权重。
举例来说,我有5个因子的Z-score,对应的股票池里有300只股票,并且收集了60个月度return。我们可以使用如下公式估计每个z-score对应的敞口(exposure):
通过以上这个panel regression可以让我们获得各个因子上Z-score的最佳组合,因为该regression利用了z-score和return的variance-covariance matrix的信息。其中$ \gamma_i$代表了一个常量,$\delta_k$是regression运行后产生的系数(coefficient),用于表示对应的因子对return的贡献程度。$\epsilon_i$ 是error term。$\delta$就是我们需要的各z-score因子的最优组合。
以上这个Panel regression使用了Fix-Effects模型,参见下文。
Panel Regression 简单介绍
用于panel regression的数据有2个维度: cross-sectional 加 time-serise,如下图所示。
Panel Data可以让你控制那些你无法观测的变量例如文化因素或是不同公司之间业务实操上的区别;还包括那些随着时间而改变的变量,但这些变量在不同的实体间则保持稳定(例如:国家的政策,央行的管理,国际间的协议等)。也就是说panel data能解释个体的异质性。
通过panel data,你可以在不同层次的分析中(例如:学生,学校,区,市)引入对应变量,适用于多层次建模或层级关系建模。
Panel data在数据收集方面会面临一些问题(例如抽样设计,样本覆盖),对于微观panel会面临无应答的问题,对于宏观panel会有跨国家依赖关系(如:国家间的correlation)
为何不能直接把panel data直接用linear regression进行处理(Pooled ordinary least squares)。假设我们的模型是:
为了能是linear regression 输出有效的结果(coefficient) 需要满足如下这些前提:
- Covariates are Exogenous:$\epsilon_i$ 的期望值为0
- Uncorrelated errors:$ Cov(epsilon_i, epsilon_j) = 0 $
- Homoskedastic errors: $ Var(epsilon_i) = \sigma^2 $ 即方差保持稳定
显然,对于panel data来说,以上每一条几乎都很难满足:
- Covariates are Exogenous:无法满足是因为panel data一般都包含了无法观测到的特征(上文已提及的文化因素等),因此$\epsilon_i$ 的期望值不为0
- Uncorrelated errors:无法满足是因为panel包括了time serise维度,一般会有correltion
- Homoskedastic errors: 如果将panel data混在一起用Pooled ordinary least squares进行处理,显然不同个体的Var很难保持相同
那么对于panel data 有哪些处理方法?最常用的有以下两种:
Fixed effects
当你只关心那些会随着时间而改变的变量会对结果产生何种影响的时候,应该使用fixed-effects (FE)。
FE用来研究在同一个实体内(国家,个人,公司等)预测变量和输出结果之间的关系。每个实体拥有各自的特征,这些特征可能会或不会影响预测变量(例如,作为男性或女性可能对某些问题的看法有所不同;或是某些国家的政治体制可能对贸易或GDP产生影响;或是某家公司的业务实践会对股价产生影响)
当使用FE时,我们假设实体内的一些特征会影响预测变量、输出结果,或造成预测变量、输出结果的偏差。这实际上是关于实体的错误项(error term)和预测变量之间的相关性的假设背后的原理(对应上文提到的前提条件:Covariates are Exogenous)。FE剔除了那些不随时间改变的特征的影响,使我们能评估预测变量对输出结果的净影响。
下图显示了FE模型:

另一个关于FE的重要假设是那些不随时间改变的特征对每个个体来说都是唯一的,不会同其他个体的特征有相关性。每个实体是不同的,因此实体的错误项(error term)和常量(所谓的截距,用来表现个体的特征)不应和其他实体的error term和常量有相关性。如果error term之间有相关性,那么FE就不适用,因为无法用该模型做出准确的推断,而你的模型需要考虑该相关性(可能利用下面所讲的random-effects),这也是Hausman test的原理(用来判断是使用Fixed effects 还是Random effects)
如果你不清楚上面说了什么,那就记住下面的话:FE剔除了那些不随时间改变的特征的影响,便于我们研究什么因素造成了实体内部的改变。
简单说一下实现方式:基本思路就是:
也就是dependent variables 和 independent variables在时间维度计算平均值,并在time series的数据中减去该平均值。上式中$c_i$是无法观测到的特征,对于FE 模型来说,$c_i$不随着时间而改变,那么易知$ c_i == \bar c_i $,因此就能将$ c_i $消除。
Random effects
与FE有所不同,random effects (RE)模型背后的基本原理认为实体间的变动被认为是随机的,并且同independent varialbls不相关。FE和RE最重要的区别是各个无法观测到的影响是否体现了同independent varialbls具有相关性的因素,而非这些影响是否是随机的。
如果你认为不同实体间差异会影响到dependent variable,那么你应该使用RE。
RE的一个优势是你可以在你的模型里引入不随时间改变的变量(如:性别)。但在FE模型里这些变量会被并入截距(intercept)(注:因为在Panel regression中,不同实体有各自的截距)。
RE假设实体的错误项(error term)同预测变量之间无相关性。这使得不随时间改变的变量可以作为解释变量(explanatory variables)出现在FE模型里。
下图显示了RE模型:
选择时间间隔(time interval)和时间区间(time period)
另外两个相互关联的问题也会影响到数据的质量:
- 数据之间的时间间隔该怎么取?
- 数据需要覆盖多久时间跨度?
理想情况下,时间间隔应同你的投资期保持一致(如rebalance的周期)。如果投资组合每月会做一次rebalance,那么就以月度为间隔。如果投资组合每年做一次rebalance,那么就以年度为间隔(其实目的就是为了计算对应间隔下的return)。这么做使得后面的分析变得更为简单。
然而实际情况可能不是那么简单。例如某些因子同return的关系可能在月度上是稳定的,但是在年度上则不明显。在这种情况下,如果你依旧选择年度时间间隔那显然就不合理,即使你rebalance的频率是以年度为单位。另外,必须小心的一点是:时间间隔也不能取得太小!这会导致预测结果的精度变差。原因其实很简单,越是短期则股价的波动越趋于随机而非由相关因子的敞口决定。
再来聊一下样本时间区间(sample period)。sample period也会影响预测的精度。如果time period太短,那就会导致其包含的time interval太少,使得预测精度变差。一个常用的原则是样本越多精度越高。然而,如果样本的时间跨度太长,一个潜在的问题是股票的return同因子敞口之间的关系可能发生了改变。不太可能说因子的风险溢价在10年时间里都能保持稳定不变。
这里提供几条比较实用的经验:
- 当使用monthly interval时,样本数据需要包括36至60条time interval,也就是说total time period为3到5年。
- 当使用weekly interval时,样本的数量一般需要超过60条,也就是说总的time period会少于3年。
- 当使用季度或年度interval时,interval的数量会少很多,而总的time period一般会大于5年
实现
确定time interval
首先确定确定time interval。我的回测使用的是半年做一次调仓。但是,如果用半年作为interval那估计差不多要10年的历史数据甚至更多。我觉得还是用月度做为interval,理由是:长期(半年)的return是由短期(一个月)的return构成的。具体来说,策略中的8个因子在每个月或多或少都发挥着一定的作用。
确定sample period
接下来,对于sample period来说,使用3年跨度,那么样本中有36组数据。
如何更新z-score权重
并且使用滚动更新的策略。具体来说每年更新一次z-score权重。每年有两次调仓,分别在:
- 1季报:4月30日以后的第一个交易日。
- 3季报: 10月31日以后的第一个交易日。
这两次调仓将使用相同的优化后的z-score权重,因此在每年的4月30获取前3年(36个月)的历史数据,包括每个月月初的8个因子的z-score以及对应该月的return。
历史数据
为了方便panel regression的运行,将历史数据导出为csv格式,包括以下各列:
- stock_id,股票代码
- date,日期
- ev_to_ebit_ratio,EV / EBIT
- d_to_e_ratio,book debt-to-equity ratio
- chg_d_e,Change in book D/E
- accrual,(NI-CFO)/TA
- revenue_growth,Revenue growth
- m3m,3-Month price change
- roic,return on invested capital
- roic_change,Change in ROIC
- return,interval return
测试结果
结果同我的预期有相当大的差距。。。
我使用R的plm包,运行fixed-effects model,历史数据使用了2017到2020年这3年的monthly return,获得如下结果:
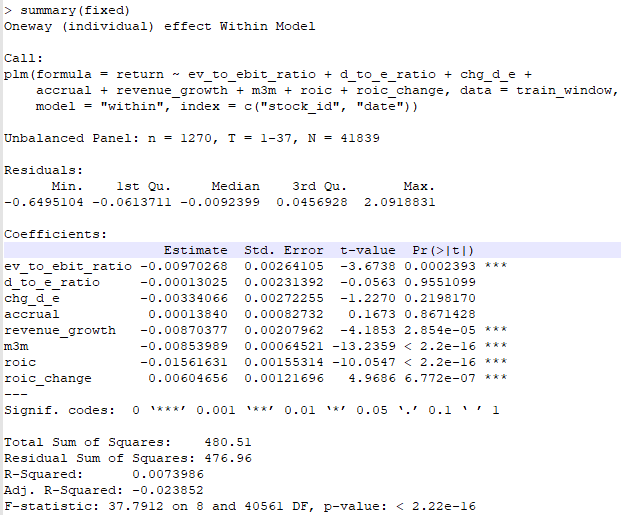
R-Squared=0.0073986,相当于说这些特征同return之间几乎没有相关性,吐血了。。。另外有几个特征对结果的影响同预期正好相反:
- accrual, 预期他应该对return产生负面影响,因为accural越大说明公司在财务方面存在潜在问题的可能性越大,那对应的return应该下降。但是,结果显示accrual的beta为正,虽然t值不显著。
- revenue_growth,预期应该对return产生正面影响,因为收入增速提高对应return升高。但结果显示beta为负,而且显著!
- m3m,这是一个动量特征,预期应该是同return正相关。但是结果显示为负,且显著!
- roic,这个代表了公司的质地,应该同return正相关。但是结果显示为负,且显著!
我还使用了5年quarterly return做了测试,结果也差不多。
注视了上面的结果良久之后,我想到一个问题,就是特征对应的值都经过normalize的处理,也就是转换成了z-score,但是,这个转换是在cross-sectinoal的维度进行的,因此在不同的时点,相同的特征就没有了可比性,例如,roic从t1到t2是增长的,但是因为在t1和t2分别对roic计算了z-score,因此,这个增长的趋势可能就被消除了。我重新用raw data(未经normalize处理)跑了panel regression,结果参见下图:
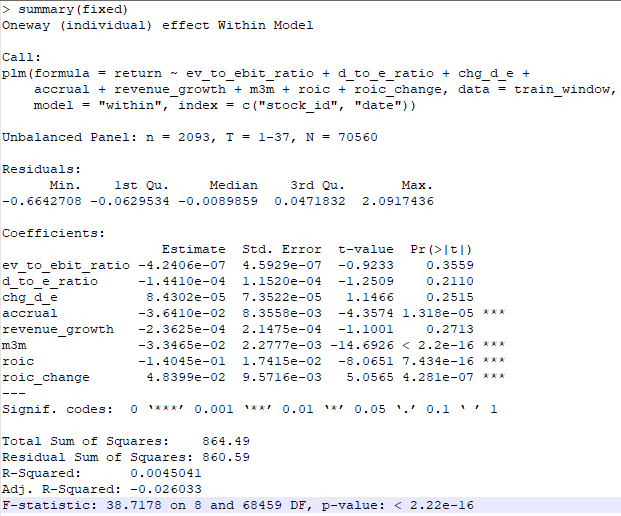
从r-squared角度来看依旧没有什么大的改变。
总结&思考
还是要本着实事求是的精神对测试结果进行总结吧。首先,利用panel regression对z-score权重进行优化理论上可行,但实际应用过程中可能无法得到确定性的结果。比如本篇得到的结果就无法应用,因为甚至连特征和收益的相关性都出现了同预期相反的情况。
个人觉得这些特征都符合economic sense,我的预期是panel regression产生的结果应该有一个比较高的r-squared,至少也应该有个10%吧。但是实际市场表现取同预期产生了矛盾。那是什么原因,接下来该怎么办?
- r-squared几乎是0说明这些feature对return没有产生什么实质性的影响。那么会是什么原因呢?是因为3年的period太短,需要从更长的周期来看(unlikely)?还是这些feature选择有问题,或是中国市场有自己的特性?还是我的panel regression设计上出了问题?这需要进一步的分析研究,但我目前还没啥好的想法。
- 接下来该怎么办?我个人觉得这些feature是符合economic sense。但是,panel regression并不支持我的观点。在这种情况下,我会保留等权重的aggregate z-score,同时需要更多的人工干预,或者说,不能完全依赖模型给出的结果。以模型给出的结果为基础,接下来需要人工筛选,比如对财报和行业进行做更深入的分析以获得最终的入围标的。
我个人觉得量化投资还是要基于道理上说得通,也就是符合economic sense。在出现矛盾的时候,比如量化跑出了好的结果但是无法给出合理的解释,或是符合economic sense但却无法获得预期的return,我会偏向选择符合economic sense这一边。当然,随着自己在知识和经验上不断地积累,以前觉得没道理的事情可能就变得有道理了,反之亦然。一定是一个不断迭代不断自我否定的过程。
最近写了很多代码,也做了很多的测试。感觉基础方面的工作已经七七八八基本就绪了,包括:
- 如何计算市场的expected risk premium:基于FCFE重新计算中国市场隐含风险溢价,用于计算股票的discount rate
- 如何使用bottom-up beta:关于自底向上贝塔(bottom-up beta)的10个常见问题,用于确定个股的beta
- 如何确定DCF的永续增长率g:无风险利率,GDP增速以及DCF中的永续增长率g,用来对股票进行估值时确定terminal value
- 如何估计市场总体风险:一个简单的衡量股市估值高低的方法,用于确定投资组合的风险敞口
- 设计了一个基于价值投资风格的screen:一个基于价值的screen(筛选器),用来获得备选股票
除了以上这些,我还打算加入外资跟踪策略和超跌策略。因此,一个股票主动投资系统基本搭建起来了。接下来就是不断实践和总结了。我打算每周定期更新相关的数据。并在雪球上建两个组合。一个是纯量化策略基于本文讨论的screen,没有人工干预。另外一个是主动投资组合,基于这个screen但会加入自己的分析和判断。因此,接下来的主要工作就是拼命看公司了。